
この記事の狙い
下記のようなデータフレームの変換を行います。

変換元のデータフレームは、1行に複数のデータがカンマで区切られている文字列を持っています。変換先は元のデータを分割して一次元化したデータフレームです。
ここでは行数ではなく「,」で区切られたレコードの数をカウントします。紹介する方法は1列のデータのみに適用できます。上記のID列以外に列がある場合は適用できません。
この記事で実行するコード概要
# 1.ライブラリのインポート
import pandas as pd
import itertools
# 2.データセットの用意(省略可)
id_list = {"id" : ["1451", "1597, 0456", "7456", "1345, 7315", "7894, 6769, 2986"]}
df = pd.DataFrame.from_dict(id_list)
# 3.要素ごとに分割
df = (df['id'].str.split(','))
# 4.一次元にならす
df = list(itertools.chain.from_iterable(df))
# 5.カウントする
len(df)それぞれの部分の挙動を細かく見ていきます。
ライブラリをインポート
import pandas as pd
import itertools今回はデータフレームを扱うためのpandasとループ実行のためのitertoolsを使います。
Pandasは頻出ライブラリですが、頻度が高くないと思うので説明リンクを張っておきます。
https://docs.python.org/ja/3/library/itertools.html
データセットの用意(省略可)
id_list = {"id" : ["1451", "1597, 0456", "7456", "1345, 7315", "7894, 6769, 2986"]}
df = pd.DataFrame.from_dict(id_list)
辞書型で作成したデータを from_dictでデータフレーム型に変換します。
ここは私が元々持っていたデータがデータフレーム型だったため、一度変換して再現性を出していますが、結局リスト型にしてしまうので、元々リスト型でデータを持っている場合は特に変換不要です。
型はtype()で調べます。
なお、この段階でカウントしようとすると、行数カウントで5になります。
要素ごとに分割
# 3.要素ごとに分割
df = (df['id'].str.split(','))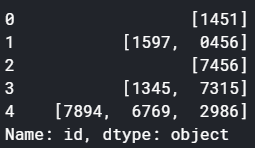
今回、各要素が「,」で区切られていたため、「,」で分割をしました。
状況により、中身を変えればOKなのでシンプルです。
一次元にならす
# 4.一次元にならす
df = list(itertools.chain.from_iterable(df))
https://docs.python.org/ja/3/library/itertools.html#itertools.chain.from_iterable
解説があまり書かれていないので、個人的にはわかりにくかったですが、これで一元化できます。
カウントする
# 5.カウントする
len(df)
これで、すべての要素をカウントすることができました。
また、dfをデータフレームに直して、マスターデータに登録されているか確認する、などのユースケースがあります。
# おまけ:データフレームに直す場合
result = pd.DataFrame({'df': df})まとめ
今回は、一行に複数のレコードを文字列で持つ列を一次元化し、レコード数をカウントしてみました。こういったデータは世の中には結構多いデータの類ですが、データ分析上は使いにくいですよね。
ただし、今回紹介した方法は、レコードの重複を調べてデータ数をカウントするなどには十分ですが、他の列の情報があった場合データが抜け落ちてしまいます。流用に限りがあり賢い方法ではないかもしれません。

