
Google Cloud Associate Cloud Engineerの合格に向けて勉強したことをまとめています。
ほぼ自分のための備忘録です。順番も適当です。
Serverless Computing
代表的な3つのサーバレスコンピューティング環境についてまとめる。
どのサービスでも従量課金制になっており、リクエストがないときにはゼロスケーリング可能。
Cloud Run
コンテナ化されたアプリケーションを素早くデプロイ、スケーリングできるプラットフォーム。
以下2つの種類がある。参考:GoogleCloudBlog – GKE と Cloud Run、どう使い分けるべきか
- マネージドCloud Run:Googleがマネージする一般的なCloudRun。リクエスト数に応じて自動スケーリングも行う
- Cloud Run for Anthos:アプリケーションをAnthos GKEクラスタ上にデプロイする。kubernetes環境を使えるので、高度なネットワーク構成(websocketなど)やGPUの利用などが可能になる。
※ Cloud Run for Anthosではクラスタの管理にノードが必要なため、完全なゼロスケーリングはできない。
Cloud Function
サーバ管理が不要で、イベントドリブンに簡単なAPIを動かすときに最適なプラットフォーム。
ここでのイベントは、CloudStorage内のデータが作成・削除されるなどといったイベント。Pub/Subと連携することで、事前に設定したイベントに基づき任意のAPIを起動することが可能。
App Engine
ウェブアプリケーションの開発に適したプラットフォーム。
AppEngineはリージョンサービスであるため、一度デプロイすると各ゾーンで冗長的に利用可能。デプロイ先のリージョンを変更するためには、新しいプロジェクトを作成し、アプリを再デプロイする必要がある。
また、Cloud Pub/SubとはCloudClientLibraryを利用して統合する必要があるため、CloudRunやCloudFunctionほどには気軽にPub/Subとの連携は不可。
Big Query
マルチクラウドデータウェアハウスで、主にビッグデータの分析に利用される。AWSのAmazon Redshiftと似たサービス。
料金はMB単位のデータ処理容量に基づいて決定する。データの最小処理容量は10MB。LIMIT句を利用した場合でも、出力が制限されるだけでデータ処理容量が減るわけではない点に注意。
BigQuery Data Transfer Service
あらかじめ設定されたスケジュールに従い、BigQueryへのデータの移動を自動化するマネージドサービス。
Google Software as a Service(SaaS)アプリケーション(GooglePlayやYoutube, Cloud Storageなど)や、AmazonS3、Teradata、AmazonRedshiftなどのデータを移動可能。一方で、MySQLといったDBのデータはサポートしていない。
BigQueryによるGCPのコスト管理
Cloud Billingのエクスポート機能を利用することで、BigQueryデータセットにGoogleCloudの課金データを自動エクスポートすることが可能。
エクスポートされたデータから、BigQueryによる分析が可能。
外部データソースとの連携
BigQueryでは、外部に保存されたデータに対してクエリを発行してデータ分析することが可能。
2021年6月に対応している外部データソースは、Bigtable, CloudStorage, Google Drive, Cloud SQL。
参考:外部データソースの概要
Security Command Center
Google Cloud のセキュリティとデータリスクを把握するのに役に立つ正規データベース。
Web Security Scanner
App Engine、Google Kubernetes Engine、Compute Engine ウェブ アプリケーションにおけるセキュリティの脆弱性を特定するサービス。アプリケーションをクロールして、開始 URL の範囲内にあるすべてのリンクをたどり、できる限り多くのユーザー入力とイベント ハンドラの処理を試みる。
現在のサポート対象は、ファイアウォールの背後にない、公開 URL と IP のみ。
Cloud Storage
Google Cloudでオブジェクトを保存するためのサービス。AWSのS3と同じ。
Cloud KMSを利用した暗号化の設定は、いつでも設定画面から変更可能。
一般公開データ
CloudStorage内のオブジェクトは一般公開することが可能で、その際のURLの設定は下記に従う。
https://storage.googleapis.com/[BUCKET_NAME]/[OBJECT_NAME]
ストレージクラス
コスト最適化や可用性の観点から、データの使用頻度に応じてストレージクラスを変更することが可能。AWSとの比較も行ってみる。
| アクセス頻度 | GCP | AWS |
|---|---|---|
| 高頻度 | Standard | S3標準 |
| 中頻度 | Nearline | S3標準-IA (?) |
| 低頻度 | Coldline | S3 Glacier |
| 超低頻度 | Archive | S3 Glacier Deep Archive |
整合性モデル
まずは整合性についておさらい。。。
強整合性は、変更中のデータは他の人は見れない。つまり、常に見ているデータは最新であるといえる。
結果整合性は、変更中のデータでも古いデータを参照可能。つまり、見ているデータが古い可能性がある。
この上で、CloudStorageでは、オブジェクトの書き込み・削除など下記の処理は強整合性が確保されている。
- read-after-write
- read-after-metadata-update
- read-after-delete
- バケットの一覧表示
- オブジェクトの一覧表示
一方で、リソースへのアクセス権の付与・取り消しは、結果整合性である。
参考:https://cloud.google.com/storage/docs/consistency
Cloud Logging
Google Cloud上のログを保存、分析、検索、通知できるサービス。
| 主な機能 | 説明 |
|---|---|
| Cloud Audit Log | クラウド内で誰がどこでいつ何をしたのかを調べるのに役に立つ機能。 Cloud プロジェクト、フォルダ、組織ごとに以下の監査ログが提供される。 ・管理アクティビティ監査ログ ・データアクセス監査ログ ・システム イベント監査ログ ・ポリシー拒否監査ログ |
| ログエクスプローラー | クエリーによるログの検索、分析、可視化などが可能 |
| ログアラート | 自身でログベースの指標を定義し、ログイベンに基づくアラートを設定可能 |
| エラーレポート | 意味のあるエラーや、新しいエラーを自動的に分類してくれる機能 |
Virtual Private Cloud(VPC)
クラウド上の仮想ネットワーク。GCPとAWSで設定が異なるので、ちょっと注意が必要。
| サービス | GCP | AWS |
|---|---|---|
| VPC | グルーバルにまたぐことが可能 | リージョンごとに作成 |
| サブネット | 複数のゾーンをまたぐことが可能 | アベイラビリティゾーンごとに作成 |
VPC内ではプライペートIPで通信可能なので、GCPではグローバルにVPCを組むと、効率的でセキュアな通信が可能になる。
Compute Engine
インスタンスの作成コマンドは、gcloud compute instances createとなる。
実行時に、–metadata-from-fileオプションを利用して、起動スクリプトを渡すことが可能。
インスタンスグループ
2種類のVMインスタンスグループが存在する。
- マネージドインスタンスグループ(MIG):複数の同一 VM でのアプリケーション操作が可能。自動スケーリング、自動修復、リージョン(マルチゾーン)デプロイメントなどの自動化MIGサービスを活用可能。スケーラブルで可用性に優れたワークロード処理を実現する。
- 非マネージドインスタンスグループ:ユーザー自身が管理する一連の VM 間での負荷分散が可能。
ストレージオプション
ComputeEngineで利用できるストレージオプション
| ストレージオプション | 説明 |
|---|---|
| ゾーン永続ディスク | 信頼性の高いブロックストレージ |
| リージョン永続ディスク | 2つのゾーンに複製されたリージョンブロックストレージ |
| ローカルSSD | 高パフォーマンスかつ、一時的なローカルブロックストレージ。起動ディスクとしての利用はできない |
| Cloud Storageバケット | Cloud StorageバケットをComputeEngineにマウントすることで利用できる、手頃の料金なオブジェクトストレージ |
| Filestore | ComputeEngineにNFSプロトコルでマウント可能なファイルストレージ。つまりNAS。AWSのAmazonEFS |
スナップショットについて
永続ディスクのスナップショットスケジュールは、時間・日・週で指定可能。
スケジュールの更新には、既存スケジュールを消してから新規スケジュールを作成する必要がある。
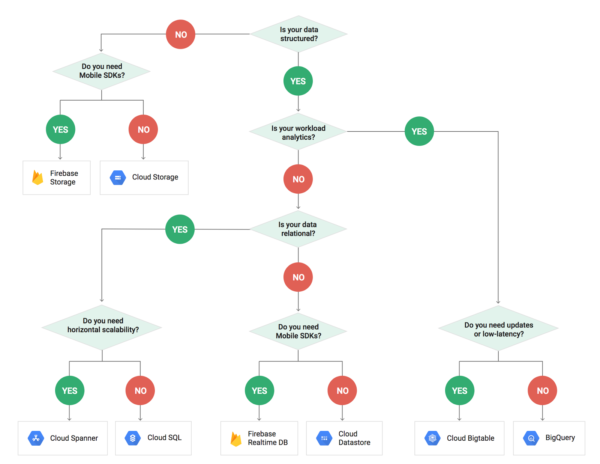
DBやストレージ関係のまとめ
DB系のサービスが多いので、まとめておく。
| データの種類や構造 | サービス名 | 説明 |
| Object | Cloud Storage | オブジェクトの保存用スト−レジ。AWSのS3 |
| In-Memory | Cloud Memorystore | RedisとMemcached向けのインメモリサービス。Amazon ElasticCache |
| Relational | Cloud SQL | MySQL, SQL Server, PostgreSQLの代替となるクラウドベースサービス。Oracleには非対応。Amazon RDS |
| Cloud Spanner | CloudSQLにグローバルな水平スケーリング機能などを追加した高機能サービス。 | |
| Non-Relational | Cloud Datastore | NoSQLのスキーマレスなサービス。key-value型。Amazon DynamoDB |
| Cloud Bigtable | 時系列データやIoTデータに最適なデータベースで、ビッグデータ向けのフルマネージドNoSQLサービス。分析向け。 |
GoogleCloudBlogに投稿されているこちらの画像がわかりやすい。
Kubernetes
コンテナ化されたワークロードやサービスを管理するためのプラットフォーム。
ここは勉強不足でまとめられるほどの知識がない…kubernetesだけで他の記事にする予定。
とりあえず、絶対に覚えておかないといけない3つの概念は下記。
- Pod:一つ以上のコンテナで構成されるコンテナコレクション。Pod内のコンテナは密に接続しており、一つの論理的なアプリケーションとして動作する。
- Service:Podsのエンドポイントを提供する。Podは再起動のたびにIPが変わるので、Serviceに設定したLabelを通じてPodにアクセスする。
- Deployment:Podの状態を自分で設定した状態に維持する。Podがスケーリングや更新が必要なときにはDeploymentがその処理を行う。
(勉強中)実際にはDeploymentはReplicaSetを管理しているかも。ReplicaSetはPodマネージャーのことで、必要に応じでPodのレプリカを作成する。
Service typeについて
Podsのエンドポイント管理であるServiceには、typeが4種類ある。ここはよく模擬試験で出題されているのでまとめておく。抽象的な概念として、ClusterIP < NodePort < LoadBalancer。
- ClusterIP:クラスター内部のIPでサービスを公開する。Pods間の通信はこれで行われる。service typeのデフォルト値
- NodePort:各NodeのIPで静的なポートを用いてサービスを公開する。つまり、外部からアクセスできるポートが提供される。
- LoadBalancer:NodePortの更に手前にクラウドプロバイダのロードバランサーを配置して外部にサービスを公開する。
- ExternalName:CNAMEレコードを利用してサービスに別名をつけることが可能。
ExternalNameは試験対策問題にあまりでない。一方で、ClusterIPとNodePortの違いはよく覚えておくべき。
基本的に、ClusterIP, NodePort, LoadBalancerの順番で機能が拡張されている。
PodとNodeとNode Poolについて
抽象的に捉えると、Pod < Node < Node Pool。
- Pod:一つ以上のコンテナグループのことで、kubernetesでは最小単位のこと。
- Node:クラスター内におけるワーカーマシン(仮想・物理は問わない)のこと。Podは全てNode上で動作していて、Node上にPodグループがある感覚。
- Node Pool:Nodeのグループのこと。NodePool内の最大Node数はクラスタ生成時に指定することが可能。手動でノード数を変更する場合は、
gcloud container clusters resizeコマンドで可能。また、自動スケーリングを設定しておくことで、Node数を動的に変更することも可能
その他
| サービス名 | 説明 |
|---|---|
| CloudCDN | 世界各地に分散しているエッジ接続拠点にコンテンツをキャッシュするサービス。キャッシュを利用することで、HTTP(S)負荷分散されたコンテンツをより高速に配信することが可能になる。Amazon Cloud Frontと同様のサービス。 |
| Dataproc | ビッグデータ処理が可能なサービス。Spark, Hadoop, Prestoなど30以上のOSSフレームワークを実行可能。AWSのAmazon EMR |
| Cloud Scheduler | 一般的にcronジョブと呼ばれるジョブを呼べるサービス。一定時間ごとに定義したジョブを実行可能 |
| Cloud Interconnect | オンプレミスとVPCの間で、専用接続によるデータ転送を可能にするサービス |
| Deployment Manager | インフラをyaml等のコードによって管理し、効率的にプロビジョニングするサービス。AWSのCloudFormation |
| ShieldedVM | OSレベルの改ざん検知やシステムの整合性確認に使われるサービス。 |
| Cloud Armor | DDoS攻撃からwebサービスを保護するサービス |
| Transfer Appliance | ラックマウント可能なストレージサーバーを利用したオフラインデータ転送サービス。 データセンターでデータをストレージサーバーに取り込んだ後、Cloud Storageデータをアップロード可能な拠点にサーバーを移動して、CloudStorageにデータを格納する。 |
| マネージドインスタンスグループの自動スケーリング | CPUの平均使用率に基づくスケーリングか、HTTP負荷分散処理能力に基づくスケーリングも可能 |

