
Kaggleのコンペティションで入門編として位置づけられている「タイタニック」の課題をPythonで実装し、提出するまでの手順を解説します。
- Kaggleに登録したけどそのあとどうすればいいのかわからない
- 機械学習をやってみたいけど進め方がわからない
- Pythonは少しやったことがある
- タイタニックを提出したがスコアを伸ばしたい(同じ方法でスコア0.756取得できます)
なお、本記事は下記Udemyの講座で学んだ内容を自分なりにアレンジしたものです。
Python・機械学習をいちから学んでおきたい方にとてもおすすめな講座です。
このページでタイタニックを提出して、もっと機械学習を学びたいと思ったら、是非履修してみてください。
Kaggleで始めるPython AI機械学習入門コース|高評価現役講師が丁寧にレクチャー

タイタニックコンペとは
Kaggleのコンペティションで開催されている「タイタニック」は、Kaggleの環境や仕組みに慣れるために最初に取り組むことを推奨されたコンペティションです。
このコンペティションでは、タイタニック号の乗客情報を元に、氷山衝突事故によって生存できたかを予想する機械学習モデルを作成し、その正答率を競います。
はじめよう
コンペページに移動
こちらから飛べます。Kaggleのページから遷移する方法は下記の通りです。
左のメニューバーから、Competitionsを選択します。
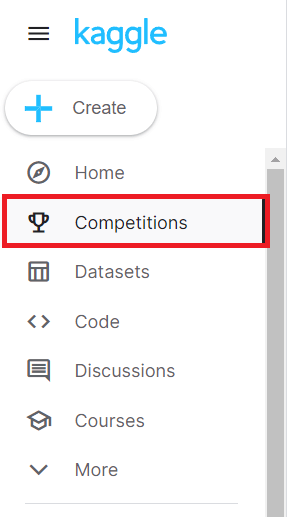
Searchボックスから「titanic」を検索すると、出てきますので、選択してください。
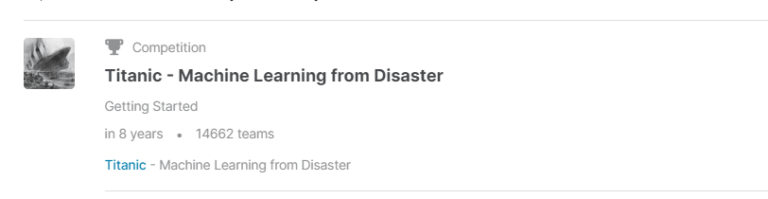
ノートの作成
コンペのページに移動したら、ノートを作成します。
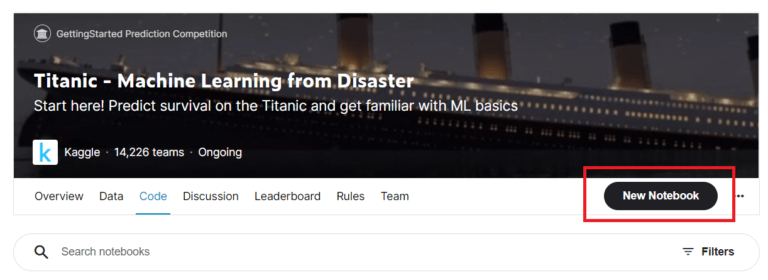
メインメニューの「Code」からもNotebook自体は作成できますが、コンペのページから作成すると、そのコンペに必要なデータが既に揃えられているのでお勧めです。
データを確認しよう
データファイルの確認
取り組むコンペで提示されているデータを確認しましょう。
コンペのデータタブに移動します。
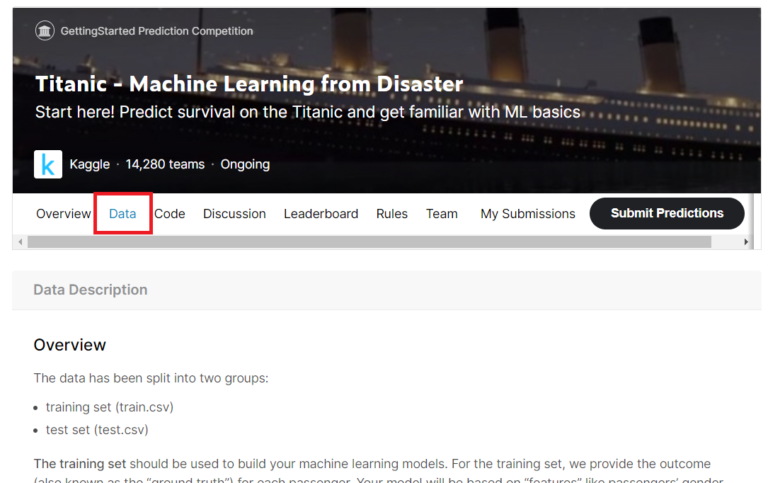
タイタニックコンペに用意されているデータファイルは以下の3つです。
- 訓練データ(train.csv)
- 検証データ(test.csv)
- 提出データサンプル(gender_submission.csv)
訓練データは機械学習モデルを作成するために使用する入力データです。
タイタニックコンペでは、モデル作成の元データとなる乗客情報とモデルで予測する正解の情報(生存)が記載されています。
検証データはモデルの予測精度を測るためのデータです。
精度検証データのため、正解の情報は提供されません。
タイタニックコンペでは、作成したモデルを使って、検証データの生存/死亡を予測します。
提出データサンプルに合わせた構造で予測結果を作成していきましょう。
データ定義の確認
訓練データ・検証データの列名は下記の通りに定義されています。
| 列名 | 定義 |
|---|---|
| survival | 生存(生存=1、死亡=0) |
| pclass | 乗船クラス(1等~3等を数値のみで表現) |
| sex | 性別 |
| Age | 年齢(xx.5の場合は推定年齢) |
| sibsp | タイタニック号に一緒に乗船した兄弟姉妹・配偶者の数 |
| parch | タイタニック号に一緒に乗船した両親・子どもの数 |
| ticket | チケット番号 |
| fare | 運賃 |
| cabin | 船室番号 |
| embarked | 搭乗港 C=Cherbourg, Q=Queenstown, S=Southampton |
ライブラリのインポート
以後の手順で必要なライブラリをインポートします。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pandas_profiling
import statistics as stデータの読み込み
次にデータを読み込みます。
data_train = pd.read_csv('../input/titanic/train.csv')
data_test = pd.read_csv('../input/titanic/test.csv')
data_gender_submission = pd.read_csv('../input/titanic/gender_submission.csv')ファイルパスは右側のデータより、ファイル名横のコピーアイコンからコピーすることができます。
データの確認
早速データの中身を見てみましょう。
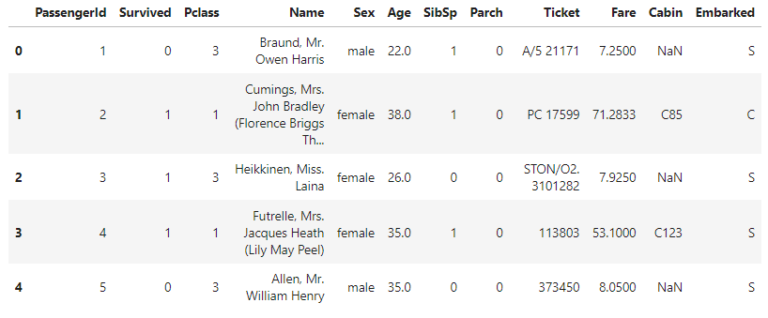
data_train.head()定義に記載のデータ項目以外に各乗客固有のPassengerIdが割り振られています。
他は定義に記載の通り、データが入っていることがわかります。
データを確認したので、もっと詳細にデータを見てみましょう。
pandas profilingでは、自動的にデータの統計データや関連性を算出してくれます。
data_train.profile_report()しばらく待って下記画面が出てくれば、完了です。
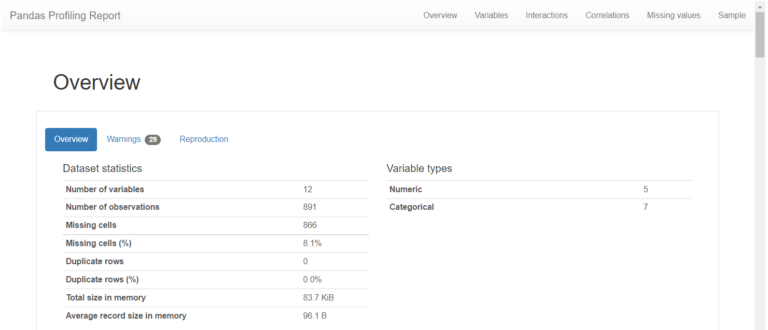
OverviewとかWarningをみて、使えそうな知見がありそうか見てみます。
私は、下記内容がこの後のモデル作成に使えそうだと思ってメモしました。
- PassengerId ・Name・Ticket・Cabinは値のばらつきが高い。
- PassengerId・Nameはすべて固有の値。
- SibSp・Parchは0値の割合が高い(≒70%)。
- AgeとCabinは欠損値がある。
データをきれいにしよう(特徴量エンジニアリング)
さて、ここまで用意されているデータを確認してきました。
ここでは、予測モデルを作成しやすいように、予測には不要なデータの削除や汚いデータを整える作業を行います。
これを特徴量エンジニアリングと言います。
訓練データと検証データの統合
訓練時と検証時で、同じ前処理をされたデータを使う必要があるので、訓練データと検証データを統合して一度に作業できるようにします。
data_all = pd.concat([data_train, data_test], sort=False)使用しないデータの削除
モデルを学習する中で、予測値に関係のなさそうなデータ項目を削除します。
私はデータ確認において、数値のばらつきが大きかったり、同じ値を持つ人が多い情報は生存率には関係しないと思ったので、PassengerId ・Name・Ticket・Cabin・SibSp・Parchを削除することにしました。
data_all.drop(['PassengerId', 'Name', 'Parch', 'SibSp', 'Ticket', 'Cabin'], axis=1, inplace=True)欠損値の補完
データは欠損値を含んでいる場合が往々にしてあります。
欠損していることに意味がある場合もありますが、今回は関連がなさそうと考え、補完することにしました。
まず、欠損値がどの程度あるかを確認します。
data_all.info()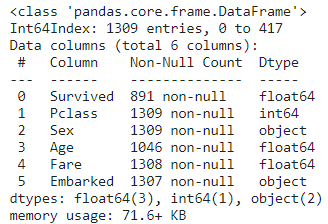
欠損値は、Non-Null Countの列を確認します。
この列は値が入っているデータの個数を表示しており、最大値を下回る行には欠損値が含まれていることを示しています。
検証データは元よりSurvivedが欠損しているので、このままにします。
ここでは、Age, Fare, Embarkedが欠損しているので、補完します。
補完方法は様々ですが、私はデータ確認において得られた知見より下記の通り補完しました。
#年齢は分散が小さいので、平均値を補完
data_all['Age'].fillna(np.mean(data_all['Age']), inplace=True)
#運賃は分散が大きいので、中央値を補完
data_all['Fare'].fillna(np.nanmedian(data_all['Fare']), inplace=True)
#搭乗港は文字列なので、最頻値を補完
data_all['Embarked'].fillna(st.mode(data_all['Embarked']), inplace=True)文字列の数値化
今回は、ランダムフォレストという方法でモデルを作成します。
この方法では、数値データを元に学習するため、文字列は数値に変換します。
#文字列を数値へ変換
data_all['Sex'].replace(['male', 'female'], [0, 1], inplace=True)
data_all['Embarked'].replace(['S', 'C', 'Q'], [0, 1, 2], inplace=True)訓練データと検証データに分ける
以上で特徴量エンジニアリングを終了しますので、統合していたデータを元に戻します。
検証データにはsurvivedが入っていないので、入っているデータと入っていないデータに分割しました。
#データもとに戻す
data_train = data_all[~data_all['Survived'].isnull()]
data_test = data_all[data_all['Survived'].isnull()]学習モデルを作成しよう
モデルは、ランダムフォレストを使って作成します。

ライブラリの使い方を確認
今回はsklearn.ensembleライブラリのRandomForestClassifierを使用します。
使い方は公式ページで確認します。
Exampleに記載の手順に従って、モデル作成は以下の流れで進めます。
- ランダムフォレストのパラメータ指定
- 訓練データを元にモデルを作成
- 検証データの予測を出力
学習の事前準備
訓練データと検証データをランダムフォレストで読み込めるにします。
#訓練データ
y_train = data_train['Survived']
X_train = data_train.drop('Survived', axis=1)
#検証データ
X_test = data_test.drop('Survived', axis=1)モデル作成・予測の出力
モデルを作成して、検証データの結果を予測します。
ライブラリを使用するとあっという間にできますね。
#ランダムフォレストライブラリのインポート
from sklearn.ensemble import RandomForestClassifier
#ランダムフォレストのパラメータ指定(デフォルト)
clf = RandomForestClassifier()
#訓練データを元にモデルを作成
clf.fit(X_train, y_train)
#検証データの予測を出力
y_test = clf.predict(X_test)提出ファイルの作成
予測結果を提出データのサンプルに従ってcsvで出力します。
result = pd.DataFrame(y_test).astype(int)
result.columns = ['Survived']
submit = pd.concat([data_gender_submission['PassengerId'].astype(int), result],axis=1)
submit.to_csv('submit_v1.csv', index=False)ノートの保存
最後までエラーがないことを確認したら、作成したバージョンを保存しましょう。
右上の「Save version」>「Save」で完了です。
提出しよう
タイタニックコンペの画面に戻り、「code」から「your work」を選択します。
保存したバージョンのNotebookを選択し、「Data」を選択します。
出力ファイル名の右にある「Submit」を押下します。
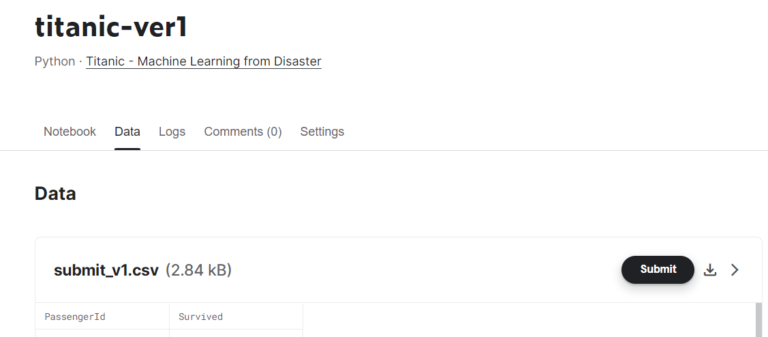
時間がかかるので、しばらく待ちます。

問題がなければ、下記ウィンドウが表示されるので、再度Submitを押下します。
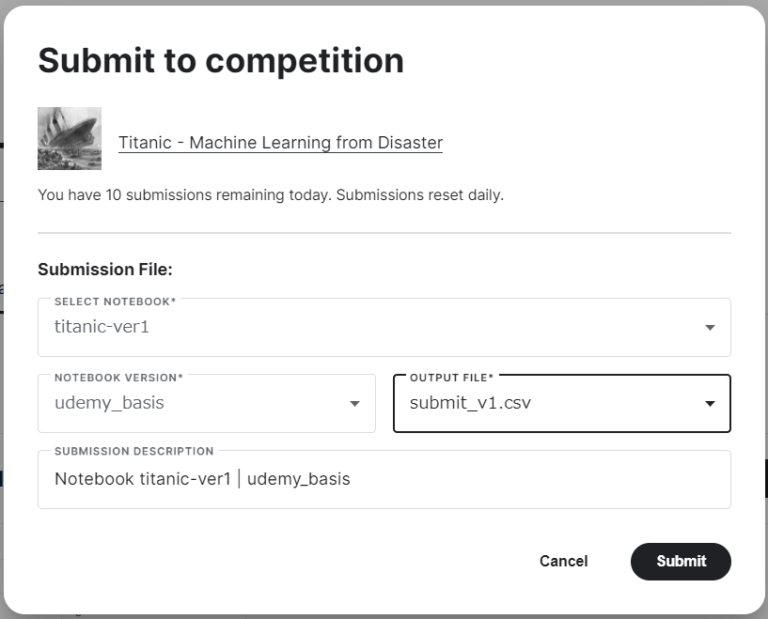
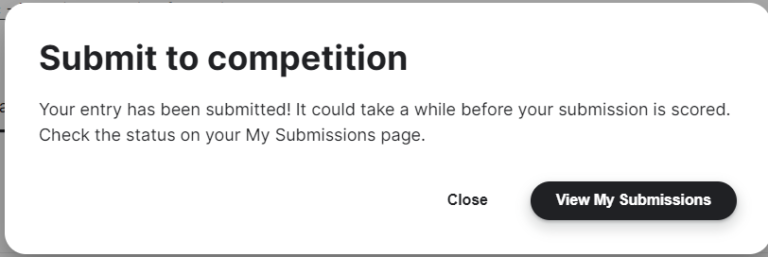
以下のウィンドウが出てくれば成功です!
「View My Submissions」から精度と順位がわかるので、確認しましょう。
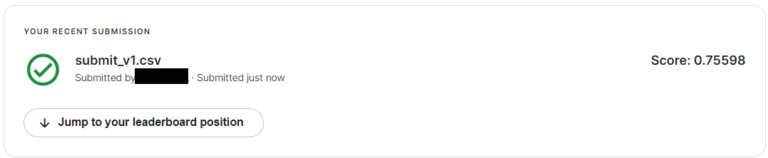
「Score」の数値は点数で、今回は0.756を獲得しました。
「Jump to your leaderboard position」から自分の順位も確認できます。
まとめ
以上でKaggleの「タイタニック」の課題をPythonで実装し、提出するまでの手順を解説しました。
一度提出できたので次は、更に精度を上げるもよし、他のコンペに挑戦するもよしです。
なお、ここで紹介した内容はUdemyで公開されている「Kaggleで始めるPython AI機械学習入門コース|高評価現役講師が丁寧にレクチャー」を自分なりにアレンジしたものです!
もっと理解を深めるためにもこちらのコースの履修をお勧めします。
Python・機械学習をこれから学びたい方に、とてもおすすめな講座です!
